
 当前位置:
当前位置:
当前位置:
当前位置:
上传日期:2023-10-19 浏览次数:
作者 | 虞景霖
编辑 | 邓咏仪 尚恩
国产多模态大模型开启公测!
进口替代的泼天富贵也有咱们大模型的一份。
来源:公开网络
就在前不久,阿里宣布开源Qwen-VL,一款支持中英文等多种语言的视觉语言大模型,这也是首个支持中文开放域定位的通用模型。
据官网说明,Qwen-VL不仅支持图像、文本和检测框等输入/输出,还能对输入的图像进行细粒度视觉定位。
什么是细粒度视觉定位?举个简单例子——要让大模型不仅识别出图像中的是一条狗,还要说出这是哪个品种,是萨摩耶还是哈士奇。
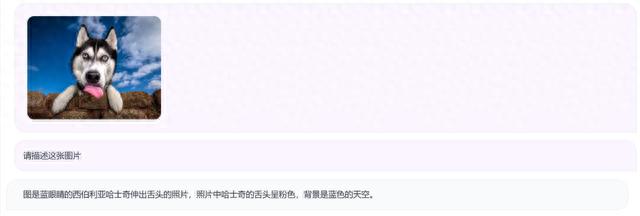
来源:Qwen-VL
现在Qwen-VL已直接开放可玩,只要进入官网,完成简单注册就ok。
官网链接:https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo/summary

来源:Qwen-VL
具体效果如何?通义千问主要从英文基准测试和试金石测试两个角度对Qwen-VL进行测试。
结果显示,Qwen-VL在零样本图像描述、通用视觉问答等多个方面的测试中都获得了SOTA(state-of-the-art,指某个领域表现最好的)的结果。
简单来说就是,超越了现阶段几乎所有国产多模态大模型。
除了Qwen-VL,本次阿里云还开源Qwen-VL-Chat。
Qwen-VL-Chat是在Qwen-VL的基础上,使用对齐机制打造的基于大语言模型的视觉AI助手,可让开发者快速搭建具备多模态能力的对话应用。
按照官方的说法,Qwen-VL的体验直接拉满,那么真正上手后究竟效果如何?实践出真知——
我们主要从知识问答、图像问答、文档问答等场景对Qwen-VL的能力进行了测评,涵盖常识问答、图像识别、阅读理解、文学创作、情感分析、信息提取等方面。
来源:Qwen-VL
首先来看看Qwen-VL的知识问答能力,来一个最近火热的话题:核污染水和核废水有啥分别?

来源:Qwen-VL
AI看似回答了一大堆,实则就是绕弯子根本没答到点子上。污染水和核废水并非同一物质,前者经过处理后可以安全排出,后者则具有高放射性,对人体和环境危害严重。
这题答错!

来源:公开网络
换一个历史常识试试呢?

来源:Qwen-VL
好像说的差不多,但也不能说它说的不对。
图像问答能力如何呢?先来一个水果试试
来源:Qwen-VL
Bingo!那它是否能对不同种类的水果进行准确定位呢?

来源:Qwen-VL
也不能说不对,虽然圈出了香蕉和菠萝,但还把石榴包括在了其中。
影视人物的识别又是否准确呢?看看AI认不认识咱的四字弟弟。
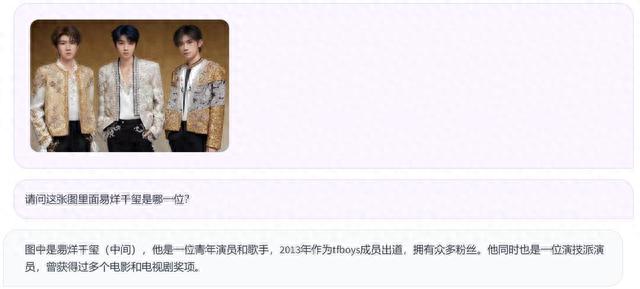
来源:Qwen-VL
很可惜,Qwen-VL又答错了,四字弟应该是最右边的那一位。
如果换成动画人物会不会好一点?

来源:Qwen-VL
这次终于对了,成功找到喜羊羊,还进行了补充信息说明,虽说附加信息中有些错误吧,但也值得鼓励。
再来试试识别“历史建筑”,回答准确!

来源:Qwen-VL
来源:Qwen-VL
但当我进一步询问它们的历史时,Qwe-VL的表现掺杂错误信息,看来不是很经夸……

来源:Qwen-VL
根据百度百科,罗马斗兽场始建于公元72-79年,长宽分别为188米、156米,围墙高57米、内高48米。埃菲尔铁塔确实建成于1889年,但高度为330米。
另外,从简答数学题来看,Qwen-VL似乎不能直接从图片中提取题目信息。

来源:Qwen-VL
接下来,当我们想上手测试下Qwen-VL的文档信息回答能力时,发现并不支持直接上传文档,至少不支持pdf、docx、txt三种常见类型的。
因此,要想测试它的阅读理解能力、总结概括能力和反事实推理能力,就只能先复制文档中的内容,再粘贴。
行吧!把我就先来看看阅读理解能力,翻译能力的测试,采用最常见的中英互译。

来源:Qwen-VL
呀,搞得不错!反过来再试试呢?
来源:Qwen-VL
你小子……算了下次不夸你了。再来看看文学创作能力,好像也比较一般。

来源:Qwen-VL
总结概括能力如何?
来源:Qwen-VL
然鹅,原答案是:曹雪芹塑造了众多逼真的人物形象。
除了上面已经测过的这些,Qwen-VL还些附加小能力,比如可以把文字内容直接生成表格。
来源:Qwen-VL
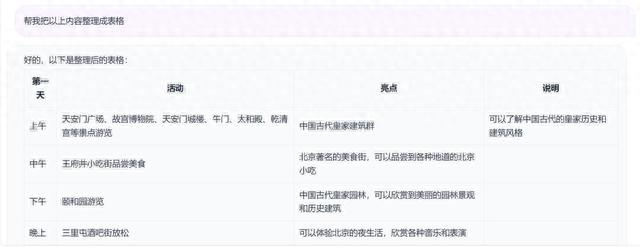
来源:Qwen-VL
好了,个人测评结束,来看看官方的测试结果咋说。
官方主要是从两个角度评估Qwen-VL的能力,分别是“英文基准测试”和“试金石基准评估”。
前者涵盖了零样本图片描述、通用问答、文字相关问答和物体描述画检测框四个方面。后者则对多种类型的图文对话进行了评估,并用人工标注描述的方法克服GPT-4不能读取图片的限制。
从测试结果来看,Qwen-VL系列多模态大模型在“零样本图像描述、通用视觉问答、文本导向的视觉问答、视觉定位”这四个方面,几乎都获得了SOTA的结果,且均可百分百复现。
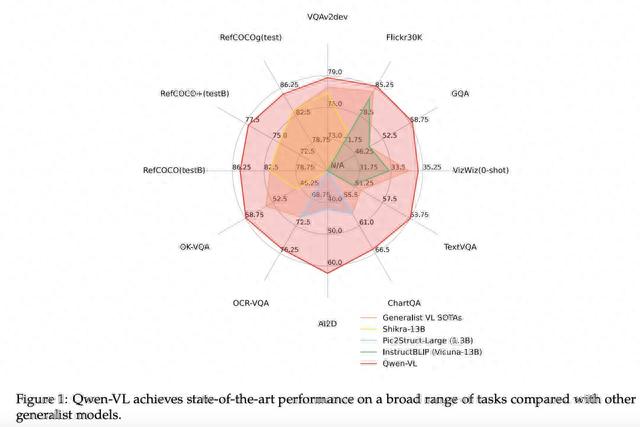
来源:Qwen-VL
具体来说,在英文基准测试的“零样本内容生成”中,Qwen-VL在Flickr30K数据集上取得了SOTA的结果,并在 Nocaps 数据集上取得了和 InstructBlip 可竞争的结果。
在“通用视觉问答”测试中,Qwen-VL 取得了LVLM(Large Vision Language Model,大型视觉语言模型)模型同等量级和设定下SOTA的结果。
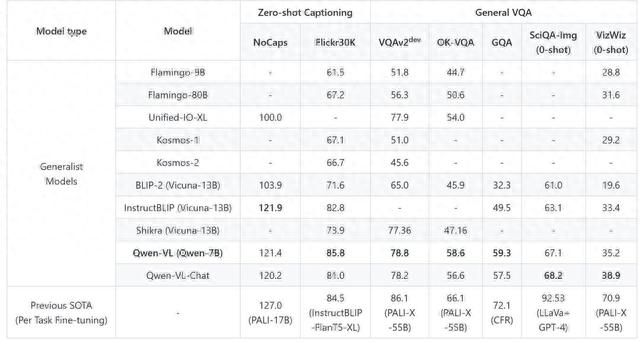
来源:Qwen-VL
而在文字相关的是识别和问答测试中,Qwen-VL表现出了超越当前规模下,通用视觉大语言模型的最好结果。
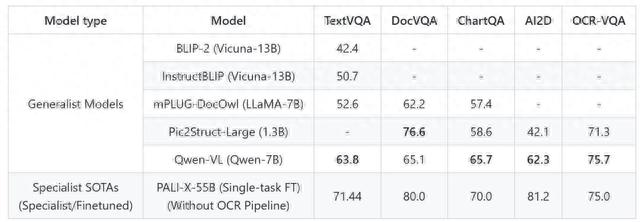
来源:Qwen-VL
在定位任务上,Qwn-VL同样表现出色,全面超过Shikra-13B,得了目前 Generalist LVLM 模型上在Refcoco上的SOTA。
Qwen-VL 并没有在任何中文定位数据上训练过,但通过中文Caption数据和英文Grounding 数据的训练,可以零样本泛化出中文 Grounding 能力。
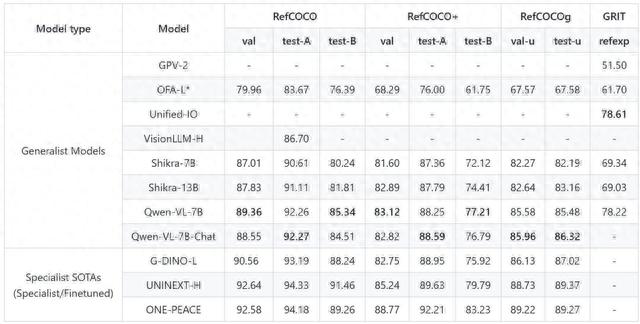
来源:Qwen-VL
技术细节上,Qwen-VL是以Qwen-7B为基座语言模型,在模型架构上引入了视觉编码器ViT,并通过位置感知的视觉语言适配器连接二者,使得模型支持视觉信号输入。
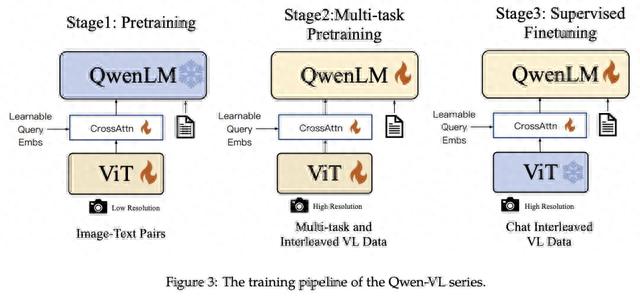
来源:Qwen-VL
具体的训练过程分为三步:
第一步“预训练”,只优化视觉编码器和视觉语言适配器,冻结语言模型。使用大规模图像-文本配对数据,输入图像分辨率为224x224。
第二步“多任务预训练”,引入更高分辨率(448x448)的多任务视觉语言数据,如VQA、文本VQA、指称理解等,进行多任务联合预训练。
第三步“监督微调”,冻结视觉编码器,优化语言模型和适配器。使用对话交互数据进行提示调优,得到最终的带交互能力的Qwen-VL-Chat模型。
目前,Qwen-VL及其视觉AI助手Qwen-VL-Chat均已上线ModelScope(魔搭社区),开源、免费、可商用。用户可从魔搭社区直接下载模型,也可通过阿里云灵积平台访问调用,平台还为用户提供包括模型训练、推理、部署、精调等在内的全方位服务。
国产大模型可谓眼花缭乱,文心一言、华为盘古、360智脑……你方唱罢我登场,一波接着又一波。在这场混战的后期,可以发现——大模型厂商们不再满足于基础的文字语言大模型,正朝着多模态大模型的方向努力。
多模态大模型,可以说是大模型发展的必经之路,就在8月28日,面壁智能宣布多模态大模型Luca2.0正式开启公测。

来源:Luca
操作同样简便,仅需登录官网,用手机号验证一下就能体验了。巧的是,和Qwen-VL一样,Luca同样只有一个聊天界面。

来源:Luca
但又有些许区别:登出后再次登录依旧可以看到之前的对话内容,并且选择重新生成回答之后仍然可以看到前几次的回答。

来源:Luca

来源:Luca
显然,可回看历史回答这一功能是好的,但生成的内容也确实需要改进。
除了阿里和面壁智能宣布公测的这两个多模态大模型,字节、360等企业也不甘落后。
字节开发的多模态大模型MagicAvatar支持将文本、视频、音频作为输入模式,通过将三者转化为运动信号,生成人类或者动画形象。360智脑则是由360集团开发的多模态大模型。根据负责人周鸿祎介绍,360智脑已经具备文字、图像、语音和视频处理能力。
目前,MagicAvatar和360智脑均暂不支持公测。
多模态大模型就像一顿丰盛的大餐,色香味接连上阵,文本、图像、音/视频等在餐桌上互相交融。
不过从测评结果也不难看出,现阶段的公布的多模态大模型大多出自新手厨师——虽然才华横溢,但难免在盐和糖的用量上稍稍出入。

 15930012679
15930012679